October 16, 2023 — 6 min read
Flipt as a Sidecar
As organizations choose to integrate a feature flag solution within their stack, they should consider several core characteristics carefully. Feature flags can be used in various ways, and often guard critical paths of functionality that an organization wants to slowly rollout, or quickly turn off in case of a disaster. This naturally lends itself to an organization asking about the consistency and availability of the feature flag solution and how fast they could get values from feature flag evaluations to their clients that are leveraging it.
At Flipt, we have had several feature requests for client-side evaluation of flags. Currently, Flipt allows only server-side evaluation, with the option of enabling cache to reduce round trips to the database. This works fine for a good amount of use cases that our users, however, client-side evaluation is still a heavily requested feature.
For client-side evaluation to work, a special client would have to be written in each desired language to asynchronously pull flag state from a central server and store the flag state in memory. Evaluations for flags in this case would certainly be faster because it removes network hops to receive an evaluation value on each evaluation request. This could be a great solution for us, however writing a custom client in each language that users may request takes time away from building other necessary features for the core product.
Acknowledging the above facts, we still want to develop a solution that works for us as a company and our users. For these reasons, we have decided to explore using Flipt as a sidecar, a very popular design pattern used in distributed systems.
The remainder of this blog post will focus on what the architecture looks like in this new world and how consumers can leverage it.
Architecture
Before talking about the overall sidecar architecture, however, it is important to note that today Flipt can be run in a variety of configurations for a storage backend. The traditional way to run Flipt is in front of an RDBMS (SQLite, MySQL, Postgres, etc.). By default, if you were to run Flipt locally it runs with a SQLite database 'next to' the Flipt binary. In addition to traditional RDBMS, Flipt can also be run in file system (FS) mode. In this mode, Flipt will periodically fetch from the target FS backend and build an in-memory snapshot of all of it's state. This process is asynchronous from any actual evaluation requests as requests are serviced on a live snapshot of state. The snapshot is only replaced with the new one once it has been built entirely.
It turns out that this architecture is perfect for doing evaluations in a sidecar as it removes one of our network hops from the evaluation call path. For reference, the different FS implementations we support are local file system, Git repositories (check out our Git blog post here), and AWS S3 buckets thanks to an awesome contributor.
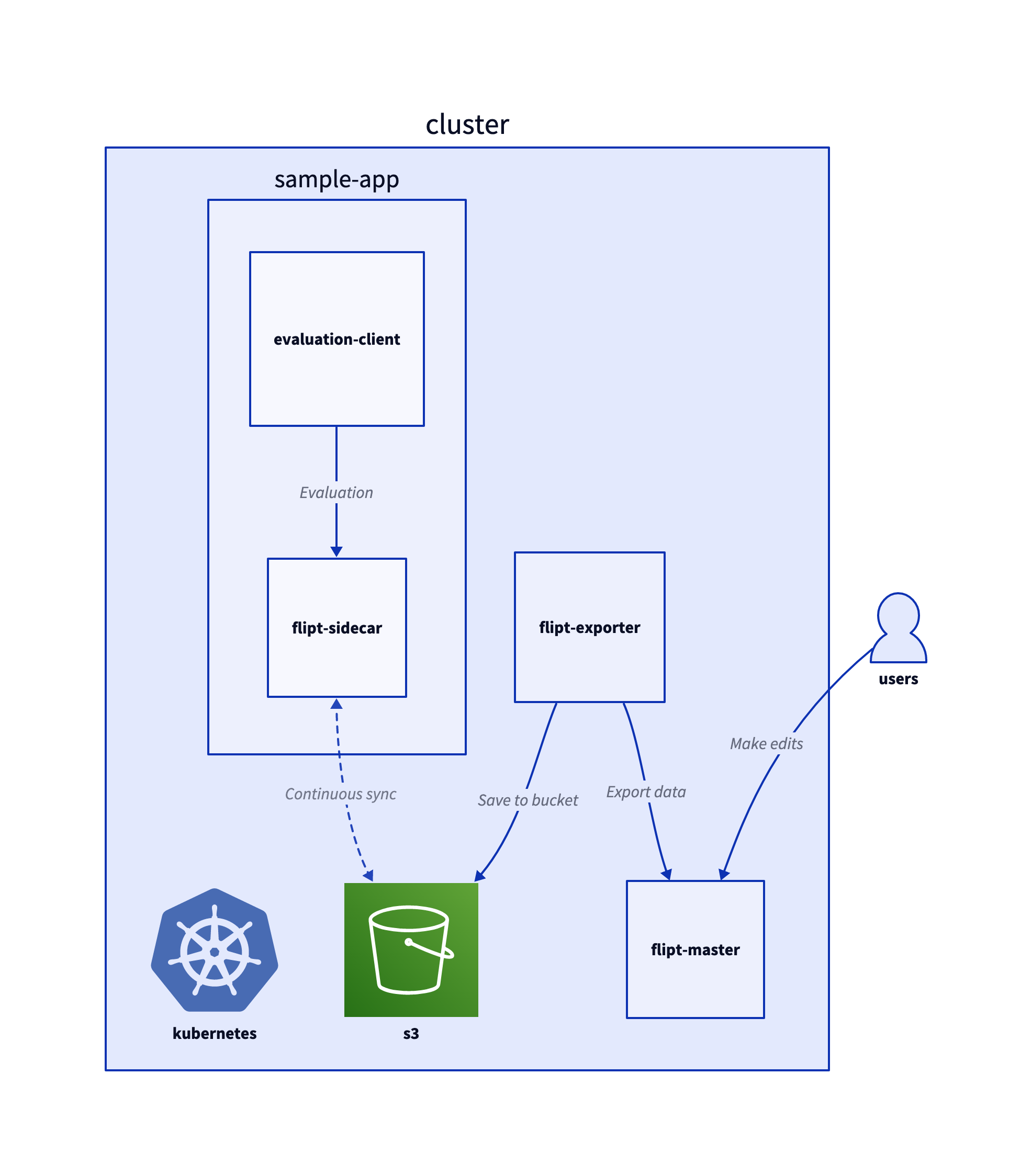
This same diagram can be found in our labs repository, where we also demonstrate how to run the proposed architecture in a minikube cluster.
In this diagram, you can see that there is a flipt-master process which will be the main source of truth for all feature flag data. This flipt-master process can be backed by any storage mechanism. The data from flipt-master will be replicated into an S3 bucket at a configurable interval via a Kubernetes cron job. Within the Flipt binary, there is an export subcommand that reads flag state data out of flipt-master and writes that data into a file. That subcommand is what is used for the cron task, and the resulting data uploaded into the bucket.
Any sidecar that will be deployed alongside a service will then run in FS read-only mode with the S3 bucket as the storage mechanism. As the service makes evaluation calls it can source the data from either the gRPC or REST API. These evaluation calls will be served from the sidecar, which will use data in memory from the S3 object store instead of having to get the data from a database over the network.
Sample Results
If you run the minikube example within the labs repository, there is also another custom application that is written in Go and serves HTML content to the client.
The HTML page allows you to make evaluation calls by selecting either the sidecar or the master process.
As the instructions state in the README, you can choose from flag_001 - flag_010 to make evaluations as these flags exist in the initial seed data to flipt-master.
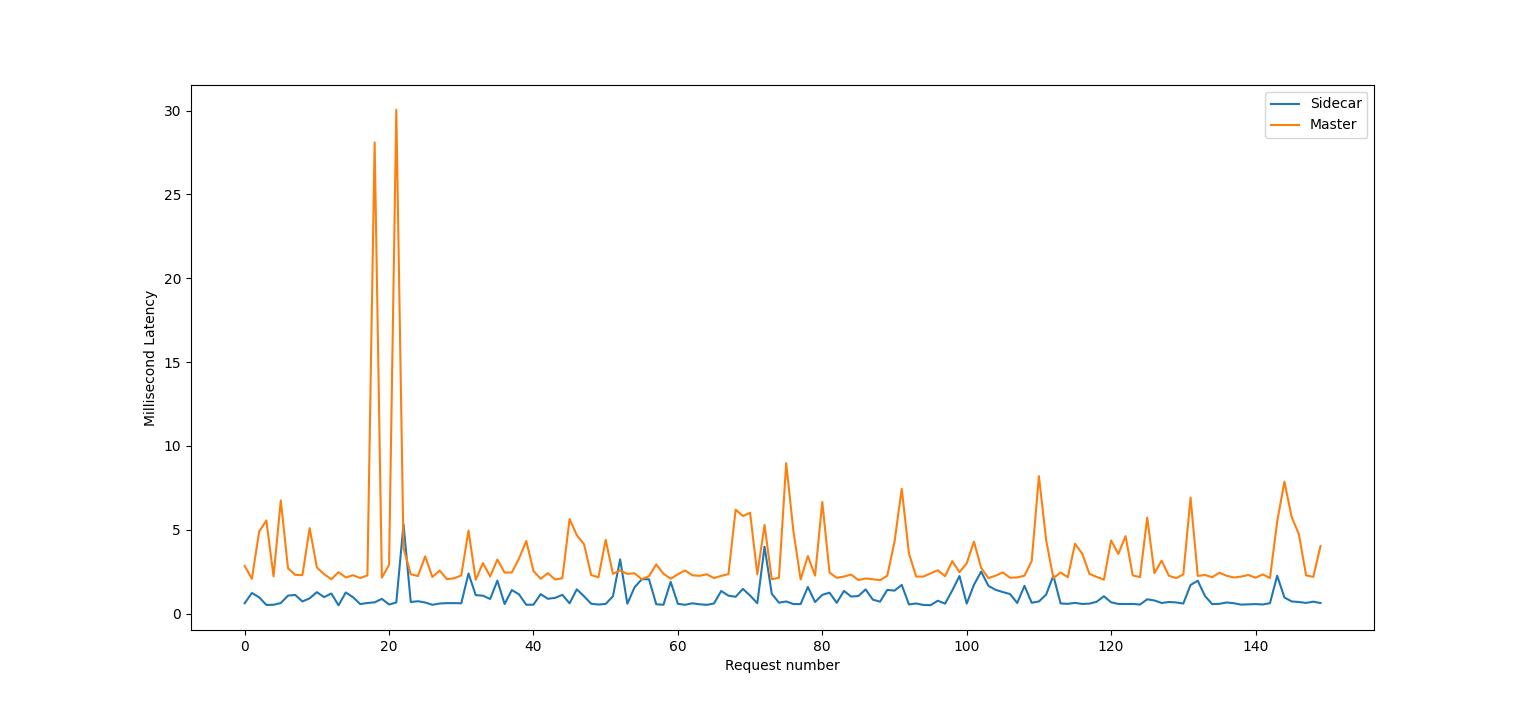
The image above was generated doing a short load test using the vegeta tool. It made requests to the sample-app's /cli endpoint at a rate of 15 req/s for 10 seconds, and dumped latency measurements to a csv file which was read and plotted using the matplotlib + pandas Python libraries. As you can see, evaluations against the sidecar were much faster (up to an order of magnitude) than evaluations against flipt-master. Keep in mind that this is just minikube as well, which is ultimately a VM running on your machine simulating a Kubernetes environment. In a real distributed environment, the difference in latency between the sidecar and flipt-master would likely be much more pronounced.
Where to Go From Here?
At Flipt, we aim to make evaluations of your feature flags as fast as possible. We realize that adding an external dependency such as Flipt has a cost and we want to minimize it. Because of this, we are devising ways to decrease evaluation time for the source as much as possible, and the sidecar approach is one way to make this happen.
However, we are not done just yet. We're experimenting with additional integrations, architectures, and deployment patterns in the coming weeks to aide in operating Flipt in a multitude of real-world environments. Stay tuned and keep an eye on our deployment docs as well as this blog for updates.
If any of this interests you or you have any questions, please feel free to reach out to us via GitHub, Discord, X, or Mastodon.
Related Posts

February 16, 2024
Elevating Feature Flag Analytics in Flipt
A deep dive into the latest release of Flipt, featuring first-class analytics for feature flag evaluations.

June 29, 2023
Announcing Flipt Labs
Today we’re announcing our open-source Flipt Labs project to show how to integrate real applications with Flipt

May 3, 2023
Audit Events for Flipt
How we leveraged OpenTelemetry for generating audit events