April 14, 2023 — 13 min read
Dagger, a ❤️ story

Background by Paul Volkmer on Unsplash
In a previous blog post, I briefly mentioned our adoption of Dagger. I wanted to take a moment to introduce Dagger and explain how we’re slowly but surely adapting our build, test (and one-day release) pipeline to leverage it.
Dagger is a programmable CI/CD engine that runs your pipelines in containers.
Dagger lets you describe your build, test and release pipelines as code, often alongside the application you’re developing it around. They support an expressive set of SDKs in multiple programming languages. At Flipt we’re using Dagger's (you guessed it) Go SDK.
Perhaps unsurprisingly, in Dagger, almost everything is a container. I say unsurprisingly since a lot of the team also gave us Docker, the technology which put Linux containers truly on the map. Each of the Dagger SDKs exposes a builder pattern interface with the primary function of describing a graph of instructions. These instructions are remarkably similar to those found in a Dockerfile, which is not a coincidence. These instructions also produce layers in resulting OCI images, which can then be published or exported from your Dagger pipeline.
I don’t know about you, but I do love a DAG and so does Dagger. The DAG (Directed Acyclic Graph) is intrinsic to what makes it such a neat solution. No points for guessing where they got their name.

A DAG is a set of vertices (the boxes) and edges (the arrows). The edges express dependencies from one vertex to the next. Before I can copy my Flipt binary into an appropriate location for execution, I first need to build it from the source. In order to run go build I first need to install Go.
DAGs allow us to express the dependent order in which operations must occur. Where this differs from a plain old sequential list, is that each vertex (entry) can have more than one (potentially) independent inputs. When you describe your workflow in this way, an execution engine (such as Dagger) can leverage the fact that fully independent operations can be executed concurrently. If you’re running your workflow on a multicore machine you may even see these operations run in parallel.
In the rough illustration above, our Go and Node components can be built independently from one another. At this stage there are no interdependencies, so they can be run concurrently. Once both operations have been completed, we bring the results together.
How does it work?
Dagger itself is comprised of a server and client architecture. The server (known as the engine) runs in a container on a target Docker host. Consumers (like Flipt) use one of the Dagger-generated and managed SDKs in one of the supported languages. These SDKs managed to initialize the Dagger engine container for you, as well making all the GraphQL API calls. Dagger has chosen to embrace GraphQL, which is a particularly good fit when you’re talking in directed acyclic graphs.
Having a GraphQL API means consumers are not strictly bound to only the SDKs developed by the Dagger team. Anyone can take the GraphQL docs and bake their own client in the language of their choice. This is similar to how we at Flipt use protobuf and gRPC and generate our managed clients from these definitions.
Under the bonnet Dagger leverages Buildkit. It was originally created by Tõnis Tiigi and now lives under the Moby (Docker) brand. It powers most of docker buildx, where Dockerfile’s are actually transpiled into llb instructions (A Buildkit structure for describing DAGs) and then solved (evaluated) by a Buildkit daemon.
If you’re familiar with the concept of git and its plumbing vs porcelain commands, I would liken the same to Dagger compared with Buildkit. Buildkit is the plumbing and Dagger is the porcelain. Buildkit exposes a fine-grained API for solving DAGs of instructions, which produce OCI images and layers. Dagger is a fast-evolving, developer-friendly layer on top. A layer focussed on solving the higher-level problem of expressing build, test and deployment pipelines in code.
I could talk about these pieces of tech all day, but for now, here is how we’re leveraging them at Flipt to build and ship quickly with confidence.
Flipt’s Build, Test, Release Pipeline
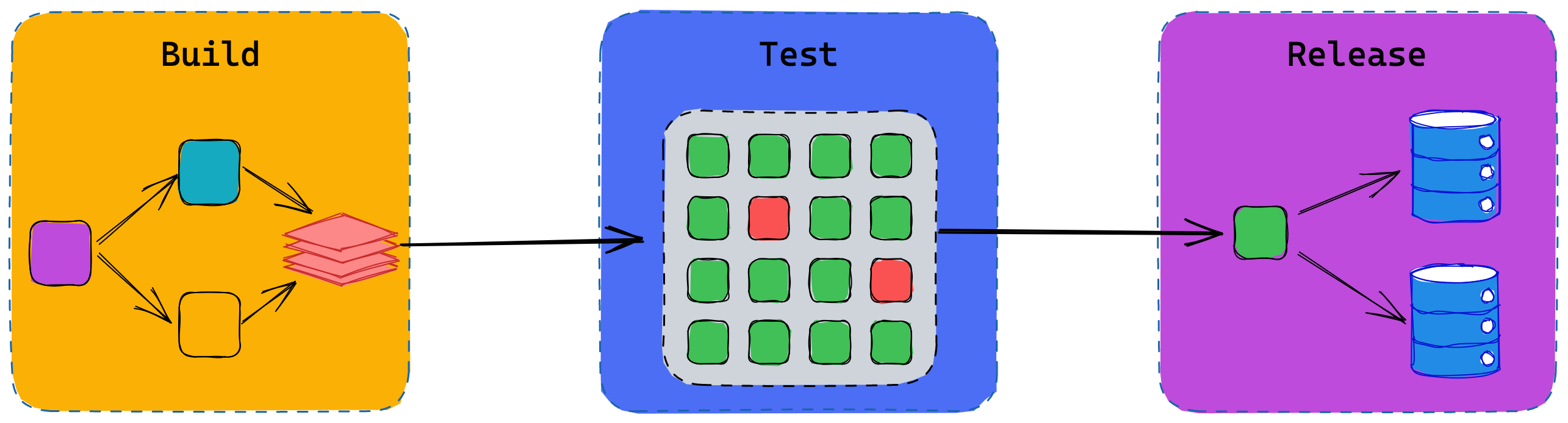
Using Dagger we’re developing the classic build, test, and release sequence.
Build Phase
The Build phase involves sourcing all the raw materials and putting the puzzle together. Effectively we perform the following five-step process:
- Establish a base image containing all the build and test tools necessary.
- Fetch all of our source code from GitHub.
- Download all the Go and Javascript libraries we need.
- Build the thing(s).
- Copy the resulting Flipt binary into its own image with only the necessary runtime dependencies.
If you’ve had experience writing a Dockerfile in the past, you may be familiar with some tricks folks employ to make better use of the Docker build cache. For example, with Go you might first add just your go.mod and go.sum files to your container before the rest of your application. Next, you will likely run go mod download in order to populate the module cache. Once this is complete then you add the rest of the application source and perform the build. You might also employ Docker's newer RUN cache features and mount a cache volume.
FROM golang:1.20
WORKDIR /src
ADD go.mod .
ADD go.sum .
RUN --mount=type=cache,target=/go/pkg/mod go mod download
ADD . .
RUN --mount=type=cache,target=/go/pkg/mod go build ./...
The same can be achieved with Dagger and the experience is familiar. The following is an illustration of using the Go SDK in Dagger to layer our graph to make the best use of caching for Go applications.
func GoApp(ctx context.Context, client *dagger.Client) (*dagger.Container) {
deps := client.Host().Directory(".", dagger.HostDirectoryOpts{
Includes: []string{
"./go.mod",
"./go.sum",
},
})
return client.Container().
From("golang:1.20").
WithWorkDir("/src").
WithMountedDirectory("/src", deps).
WithMountedCache("/go/pkg/mod", client.CacheVolume("go-mod-cache")).
WithExec([]string{"go", "mod", "download"}).
WithMountedDirectory("/src", client.Host().Directory("."))
WithExec([]string{"go", "build", "."})
}
Our pipeline for building Flipt ultimately leverages this same process, which is to use layers effectively and take advantage of the engine's layer caching, and mounted cache volumes for finer control ensuring fetched or computed assets are preserved between builds. As with Go, the same applies for Node and its dependencies. First add the dependency manifests (package.json), install the dependencies and then add the source code.
Beyond this, we have some other details which are a little more specific to how we build Flipt:
- The Flipt repo is a Go multi-module repository and uses a Go workspace to tie it all together. We read the contents of the
go.workfile to identify the multiple sets ofgo.modandgo.sumfile pairs through the repository and ensure they’re all added before downloading dependencies. client.CacheVolume(...)in Dagger takes a string to identify the cache volumes key. We build this key based on a hash of thego.sumcontents. This invalidates our cache each time our sum file changes. The idea is to keep our cache fresh over time and stop it from growing indefinitely.- We initially exclude adding the
uidirectory containing our frontend code from the Go base. Instead, we mount this directory into its own container based on anodeimage and produce a static directory containing all of our frontend assets. This resulting static assets directory is copied into the base Go container and we use Go’s embedding to bake this into the binary.
This process is defined in the function we call Base(...) and the result is a *dagger.Container. Once all the dependencies have been built and added appropriately, we build the flipt binary into a well-known path inside the last layer of the container.
There is another function called Flipt(...) which takes the resulting container from Base(...) and copies the flipt binary into a fresh, empty alpine Linux image. This image is prepared with just the runtime dependencies needed for Flipt and gives us a thin distributable image for release.
Test Phase
There are two important artifacts out of the Build phase which become inputs into our Test phase. The first is the base image (the result of steps 1, 2 and 3) with all the build and test tooling and source code. The second is the distributable Flipt OCI image (the thinner distributable image based on alpine).
In the testing phase, we first use the base image again to run our suite of Go unit tests. We run our unit test suite against each of the databases Flipt supports (SQLite, Postgres, MySQL and CockroachDB). The unit test suite requires Go to be installed, along with access to all the source code, which is why we use the base image.
The release of Dagger v0.4.0 came with support for service containers. If you’re familiar with docker-compose and how it supports multiple containers being networked together, then this feature will be familiar. It supports the ability to run containers which are used as dependencies for your workflows as network addressable services. For example, a backing database, or your very own service that you want to test over the network. This feature was crucial for connecting the various databases Flipt supports during unit testing. It also allowed us to further build out our integration testing pipeline.
In a previous blog post, we discussed building our new Go SDK. In order to gain confidence in Flipt, its API and our SDK, we leverage the full power Dagger gives us with defining our pipelines in Go.
We first defined a suite of test cases using the Go SDK, which exercises a common set of Flipt operations: create a namespace, create a flag, define its variants and segments, evaluate it, etc. The core functional requirements of Flipt as a feature flagging system.
Given how we built our SDK to abstract away details such as the transport used and authentication, we could then easily extract those (non-functional requirement) details as arguments for running our test suite. This means that we could run our suite against the HTTP or gRPC API with or without authentication enabled. With the introduction of namespaces in our latest release, we further enhanced the suite to run across a configurable namespace. Now that our test suite can be run in a number of configurations, we have an n-dimensional matrix of possibilities.
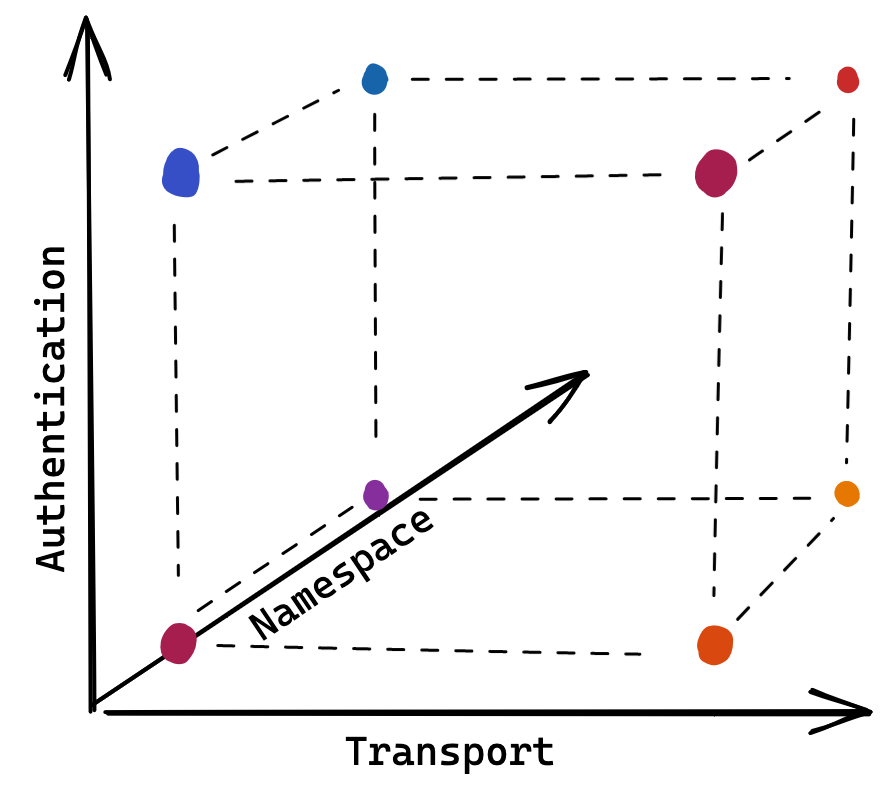
By simply using a set of nested loops in Go, we have a tidy way of expressing the multitude of possible ways Flipt could be run, giving us confidence that we’re not breaking something each time we add or change some functionality. Couple this with the ability to execute each possible configuration combination in a goroutine and we have a fast, concurrent way of executing the many permutations.
func TestAll(base, flipt *dagger.Container) error {
var g errgroup.Group
for _, auth := range []bool{true, false} {
for _, namespace := range []string{"", "some-namespace"} {
for _, transport := range []string{"http", "grpc"} {
g.Go(testFlipt(base, flipt, auth, namespace, transport))
}
}
}
return g.Wait()
}
Our pipeline is now fairly large and relatively complex. Lots of layers and concurrent operations in a web of directed edges and vertices are used to describe both build and test functionality. As with all big and complex CI/CD pipelines, they can start to slow down the more you add. This is where the advanced caching capabilities of Buildkit and Dagger come into play.
The beauty of the DAG in the Buildkit world is that each computed vertex (node) in the graph and its outputs are stored in content-addressable storage. Buildkit takes advantage of when vertices whose definitions and their inputs do not change and avoids recomputing any of these outputs. Instead, it retrieves previously computed results and uses those instead.
Locally, we have seen a full 10-minute end-to-end Flipt build pipeline with subsequent integration suite go from 10 minutes with an empty cache to 17 seconds on a subsequent run. Flipt currently references 3.2GB (!) of Go module dependencies. When you compile Flipt with an empty build cache, a fresh run will produce 1GB of build-cache entries. All this takes a considerable amount of time to fetch and compile. Dagger makes a lot of this work trivial to compute once and reuse on subsequent runs.
Buildkit has the functionality to export its cache storage to a number of remote backends so that you can persist all the hard work done computing layers and cache volumes in CI/CD environments and reuse them between separate triggers of your pipeline. Dagger today (v0.6.0) does not expose a stable API for this feature. However, the team are hard at work sweating the details so we won't have to. They’re working hard to find a DX that works for many. At Flipt we’re looking forward to when this lands, as we expect the gains in CI will be very noticeable.
Release Stage
Once Flipt is packaged and tested sufficiently, it is ready for release. Today we still use the excellent GoReleaser project to package and ship the final Docker images and binaries to their various destinations. We do suspect though, that this will move to be more Dagger driven as time goes on, ultimately publishing the artifacts produced by the pipelines that we have developed using Dagger.
All the code to define our Dagger-based pipeline can be found in the build directory of the Flipt repository. We use mage both in the root of the Flipt repository and in our Dagger pipeline code as the CLI wrapper. We’re big fans of mage and so is Dagger. For those wanting a make-like interface which is defined in Go, it is a nice intersection of the two. It also marries nicely with all of our pipeline code being defined using the Dagger Go SDK.
Dagger All The Way
Dagger is shaping up to be the solution I always wanted for CI/CD. Call me strange, but I am actually excited to develop and maintain these pipelines and I am hopeful it is going to be a sharp tool in our belts here at Flipt.
If you’re interested in Dagger then I highly recommend checking out their site, GitHub project and in particular Discord.
Equally, we really want to understand your needs in building and shipping software here at Flipt. So please do come and stop by our Discord and say hi too.
Related Posts

November 22, 2022
Authenticating Flipt
Flipt now supports Authentication as of v1.15.0

March 22, 2023
Generating the Flipt Go SDK
Using protogen to automate the generation of our Go SDK

October 20, 2022
Going All In On Flipt
We're happy to announce that Flipt is getting full-time attention from our small but growing team. Here's what that means for the future of Flipt