October 25, 2023 — 8 min read
Experimenting on the Edge
Edge computing has become a recent phenomenon for organizations to explore as they scale to meet the demands of a worldwide customer base. It is simply defined as hosting either devices or networks closer to the consumer. Implicitly, as this happens, the user can perceive a much better experience due to the interaction speed of the application to the devices and networks the application interfaces with.
For example, you can imagine that a user in the United Kingdom will benefit from having their data stored in the UK instead of anywhere else in the world. In broader terms, geographical distance from a consumer to a device or network can be significant at times and does not come for free.
In terms of feature flags, the ability to leverage edge computing suits its use case fairly well. Feature flags can often guard critical paths of an application where it is beneficial that the latency of flag evaluation is kept as low as possible.
At Flipt, we have been exploring many different ways to achieve this goal of minimizing latency for flag evaluations. We already have features such as server-side caching, hosting data in an embedded database such as SQLite, or serving flag state straight from a filesystem to name a few, so the idea of edge computing fits the paradigm quite nicely.
In recent weeks, we have been exploring running Flipt on the edge, and the rest of this post will detail the experience we had running Flipt in front of a notable edge database provider, Turso.
Turso/sqld/libSQL
Before detailing exactly what Turso provides as a service, let us briefly cover the open-source technologies and their functionalities that power Turso, libSQL and sqld.
libSQL
libSQL is an open contribution fork of SQLite and thus is fully backward compatible with SQLite. You can actually run a SQLite client over a libSQL database instance. Since SQLite is famously closed off to external contributors, the fork (libSQL) was born, which tries to cater to some of the issues or feature requests that the community wants with SQLite. There are many various distinct features that libSQL provides from SQLite such as randomized ROWID, WebAssembly, and many more.
sqld
sqld is libSQL running as a daemon in “server-mode”. It not only provides an HTTP interface over libSQL, but also replication abilities from one libSQL instance to another. When running sqld, you can declare one libSQL instance as the primary and other instances as replicas of the primary. sqld will then replicate data from the primary to the replicas. This is a very powerful feature that we will explore in more detail later in this post.
The libSQL repository provides a nice docker-compose example of how to configure sqld, and how it works overall. In addition to simple replication, sqld also provides bottomless replication in which data from the primary is continuously replicated to an AWS S3 bucket or any other S3 compatible storage such as MinIO.
Turso
Turso is a platform that provides managed libSQL with seamless replication of data to multiple regions around the world via sqld. With Turso, you can spin up a database in any region it supports as the primary, and this will be the instance that will accept all writes. Based on that primary instance, you can spin up several replicas in any other region which will serve as read-only copies and will be synced with the primary over time, providing the natural eventual consistency of data.
As we mentioned above, from the other features we already have implemented in Flipt, eventual consistency has been a constant (caching, polling of data), and is acceptable for most use cases. There are also disproportionately more reads than writes of data for most Flipt use cases, so the “extra hop” as Turso describes it to get a write into the primary is acceptable. Knowing these two characteristics, it was a no-brainer for us to at least explore this route of providing capability of running Flipt over Turso.
Flipt and libSQL
Flipt can already be run in a variety of storage modes with a slew of databases. We support the most popular RDBMS' such as: MySQL, PostgreSQL, CockroachDB, and last but not least SQLite. The already existing support for SQLite made it a relatively simple lift to support Flipt with libSQL. The functionality for this is included in v1.29.0 release! This release has support for not only running Flipt against libSQL in flat-file, embedded mode, but also in server mode with sqld over HTTP.
Although relatively painless, we did run into a couple of snags to get sqld working behind Flipt. The repository explains that currently libSQL clients are somewhat limited in terms of breadth of support. For instance, only the Rust, and Javascript clients are stable and supported while the rest of the languages are all “experimental”.
For us, the problem with the libsql-client-go client was that the main branch did not have functionality for scanning boolean types nor recognition of the TIMESTAMP data type and conversion functions from that type to a common string. We forked the repository and wrote patches for the missing functionality to get it working for the time being. We hope to contribute more to the project in the future if support for running Flipt with libSQL/Turso becomes more popular.
Flipt ‘on the edge’ with Turso
Along with the functionality of the v1.29.0 release also came an example of how to run Flipt against libSQL with replication provided by sqld. This example contains two containers of Flipt running against two containers of sqld, one primary and one replica instance.
You can access both Flipt instances and make edits via the UI, and witness the replication happening in real time. Although this works nice locally for a proof of concept, it does not show the true power of edge computing, so we opted to do an experiment with each employee at Flipt running in front of a Turso instance.
As you create database instances on Turso, the service will give you a URL that you can use to access the logical database. Turso defines a logical database as a collection of libSQL databases each with a schema and data and access to a primary instance (the primary instance itself is included in the logical grouping). The URL is then mapped to the closest instance to the user asking for the data upon query. Again, writes are routed to the primary instance by Turso, but reads can be served from any replica.
Experimenting
For our internal experimenti, we each ran Flipt locally, using the URL that Turso provides as configuration. We spun up a primary instance in IAD (Washington D.C, US), which was the closest on average for all 3 employees, and replicas in DFW (Dallas, Texas US) and LHR (London, England).
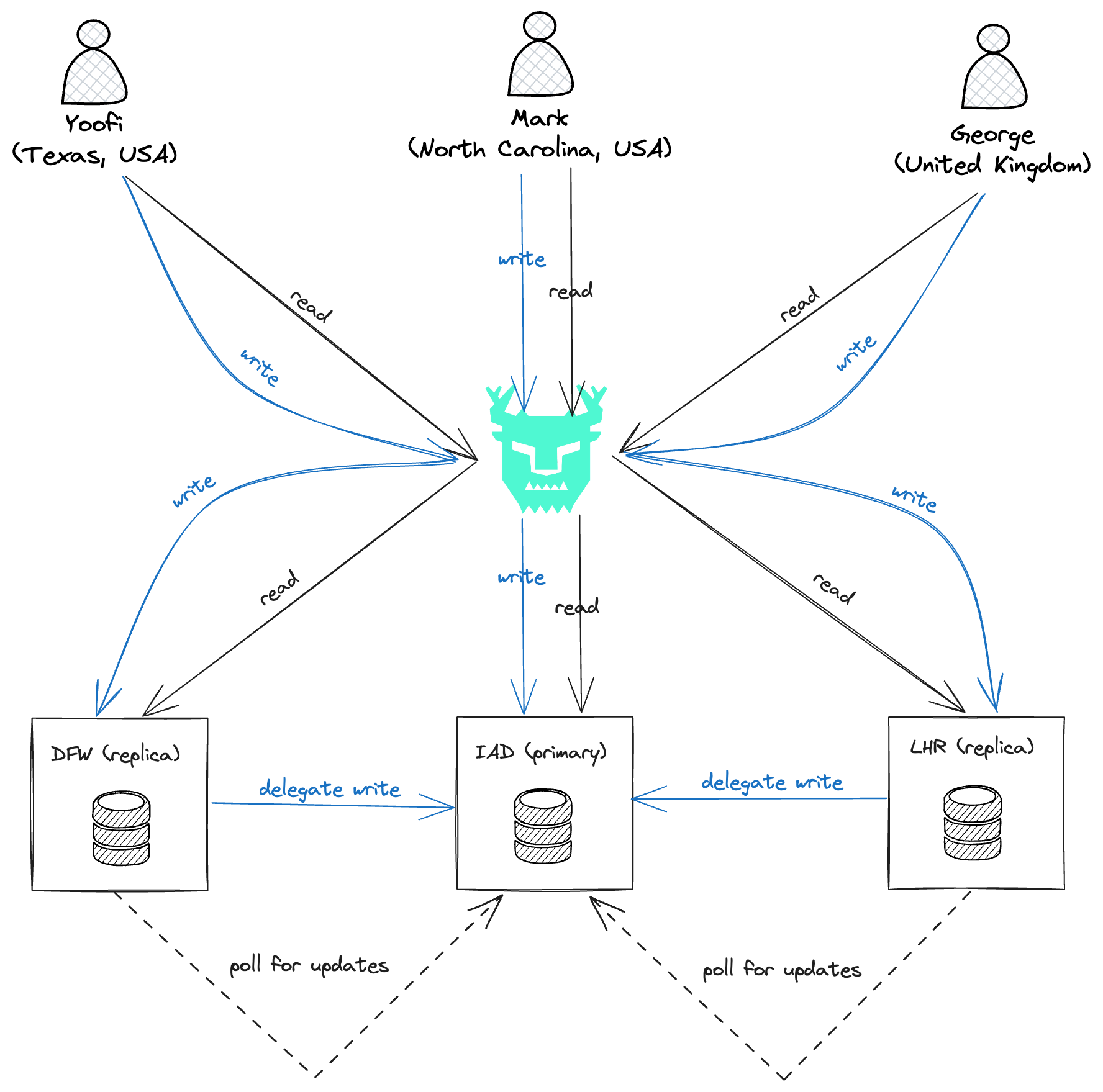
On each read of the data we encountered correctness of routing, as each employee was routed to the nearest libSQL instance. For latency, we experimented with the default state of having a replica in each region closest to an employee and took some instances away over time to see if we could witness an increase in latency. Sure enough, as we took away the replica in DFW, the employee closest saw an increase in latency, and the same for the employee near London when we took away the replica in LHR.
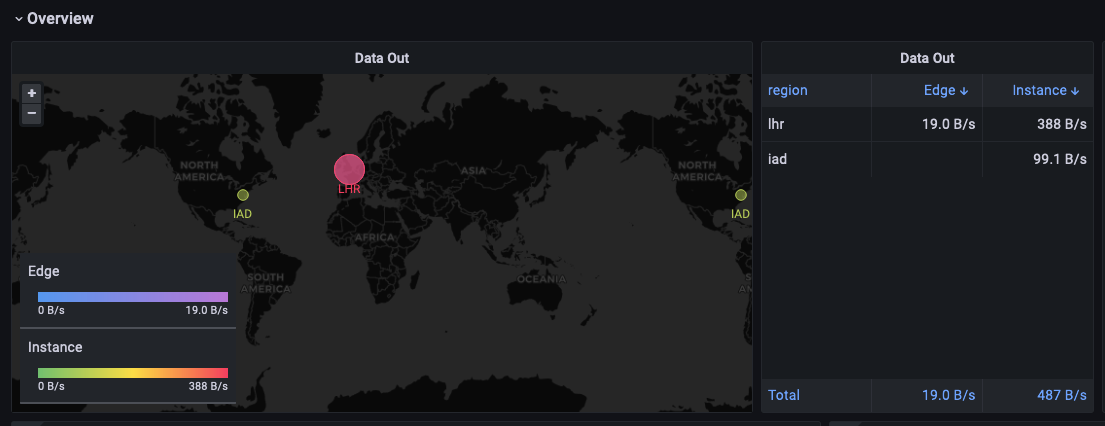
Given Turso's ability to replicate data to any region in the world in seconds, we could have spun up replicas in any region that Turso supports, and we would have seen similar results. This is a very powerful feature that we are excited to explore more in the future.
We're also looking forward to trying out Turso's embedded replica feature which would allow you to access a Turso/libSQL database via the native libSQL C binding instead of over HTTP with sqld and the libsql-client-go client. This would remove the additional latency of handling HTTP requests/responses and the marshalling/unmarshalling of JSON.
Conclusion
Turso provides an impressive experience for managing distributed SQLite compatible databases and we are excited to see how it evolves in the future.
At Flipt, we've been actively exploring how to make feature flag evaluation as fast as possible. We are very excited about the many opportunities/technologies that can aid in that mission, including running Flipt with your own data on the edge. In the previous blog post, we explored running Flipt as a sidecar which can work well in a Kubernetes environment, and now we have explored running Flipt on top of a managed edge database provider without Kubernetes.
We're continuing to explore alternative ways to run Flipt on the edge, and we're excited to share more about that going forward.
If you are interested in Flipt, edge data/computing, or how to leverage the power of feature flags in your organization, please feel free to reach out to us via GitHub, Discord, X, or Mastodon.
Until next time!
Related Posts

October 9, 2023
Generating Types for Feature Flags
How to generate and use types to make feature flags easier to use and safer

February 16, 2024
Elevating Feature Flag Analytics in Flipt
A deep dive into the latest release of Flipt, featuring first-class analytics for feature flag evaluations.

November 16, 2023
Feature Flags and OCI
How to leverage OCI registries for feature flag distribution