December 14, 2023 — 11 min read
New Client-Side Evaluation SDKs
At Flipt, we have embarked on a journey to discover new ways of speeding up flag evaluations for our users. The need for this is justifiable as feature flags often guard critical application paths where latency must be kept to a minimum. In previous blog posts, we explored using Flipt as a sidecar, and experimenting with Flipt on the Edge. Both of these experiments were successful in reducing flag evaluation latency, and also leveraged notable patterns that are becoming more popular nowadays.
Despite the success of these experiments, there remained one huge dependency, the network. On every evaluation, clients would have to go over the network to some Flipt server to get the data it needs. The difference between using a sidecar or edge database and making evaluations to a central Flipt server is that the server and database were closer to the clients which implicitly reduces latency. However, there are scenarios where the network might not be as readily available or where adding any latency to critical code paths is a non-starter.
These are a few of the reasons why true client-side evaluation has been a heavily requested feature. The idea is that clients would either poll an upstream server on an interval or be pushed data when new data arrives. When evaluation data is later requested, the clients can source it from the same memory, avoiding additional network hops. The main pro of this approach is that data being accessed from memory will always be faster than going over the network. The downside is the potential lack of data consistency since events are being realized asynchronously.
Knowing this, we have deliberately avoided naively implementing client-side evaluation, as it would require us to write the evaluation logic in every language we want to support. Not only is this a time-consuming effort, but implementation parity between evaluation logic on clients and server in this case is extremely critical, opening up the door to introducing hard-to-track-down bugs. As we explored more options, we encountered a mechanism called Foreign Function Interface (FFI) which allows a program written in one language to call and make use of functionality written in another. Leveraging this standard, we realized that the evaluation logic could be written once and clients in each native language could make use of FFI to call the evaluation logic. This would allow us to support true client-side evaluation without the overhead of implementing the dense logic over and over again.
The rest of this post is dedicated to the architecture and implementation details of our client-side evaluators using FFI.
Internal API
Before getting into how the client-side evaluation works, we should first cover how our existing server-side evaluation works as well as how new the evaluator running client-side sources the data required for evaluation.
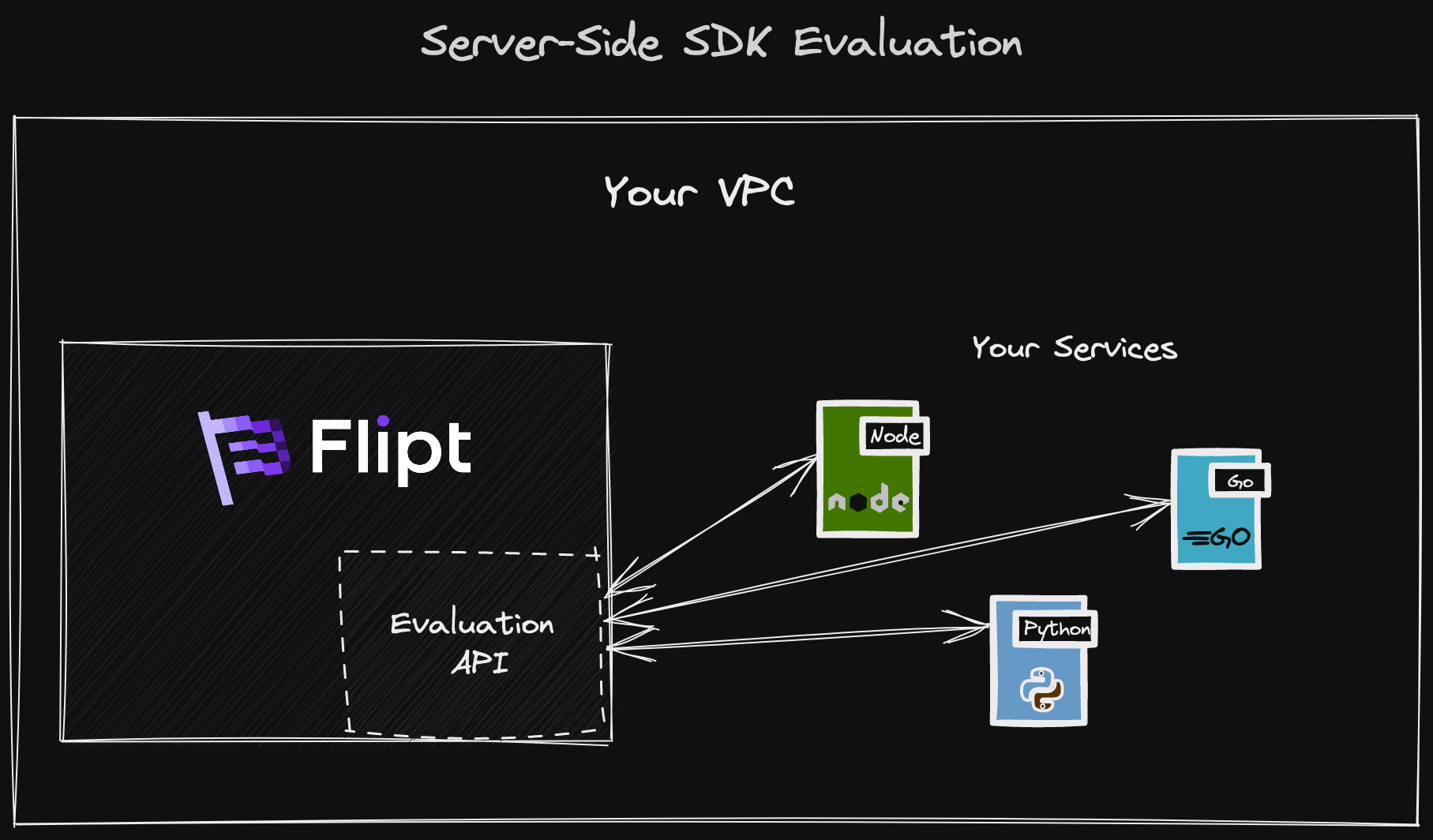
Server Side Evaluation
For server-side evaluation we have a set of public REST APIs for evaluation in which the SDKs send evaluation request data to the Flipt server, the server evaluates with data from the data backend, then returns the response to the client SDK.
These existing endpoints are:
Note: Flipt also supports interfacing via GRPC, so we also publish a set of GRPC SDKs in various languages. You can also generate your own in your language of choice.
Client Side Evaluation
To support client-side evaluation we had to rethink our approach to how data is sourced from the Flipt server. For the client-side SDKs to perform evaluation themselves without contacting Flipt for each request, we needed a way to supply them with all of the data they required. Without going into all the nitty-gritty details, this effectively meant us building a snapshot of our data model for flags, segments, rules, etc, and then shipping this serialized data structure to the clients.
Luckily, much of the work of building a snapshot of our data model was mostly already done in previous releases of Flipt, as this was necessary to support our declarative backends such as Git, OCI, and Object Store. It only took a bit of work to adapt this and put it behind a new ‘internal’ API so that we could request this snapshot state from the clients.
Note: While this API is labeled ‘internal’, it is still public-facing, we just wanted to denote that it’s not ‘officially’ meant for consumption by end users without using one of our new SDKs.
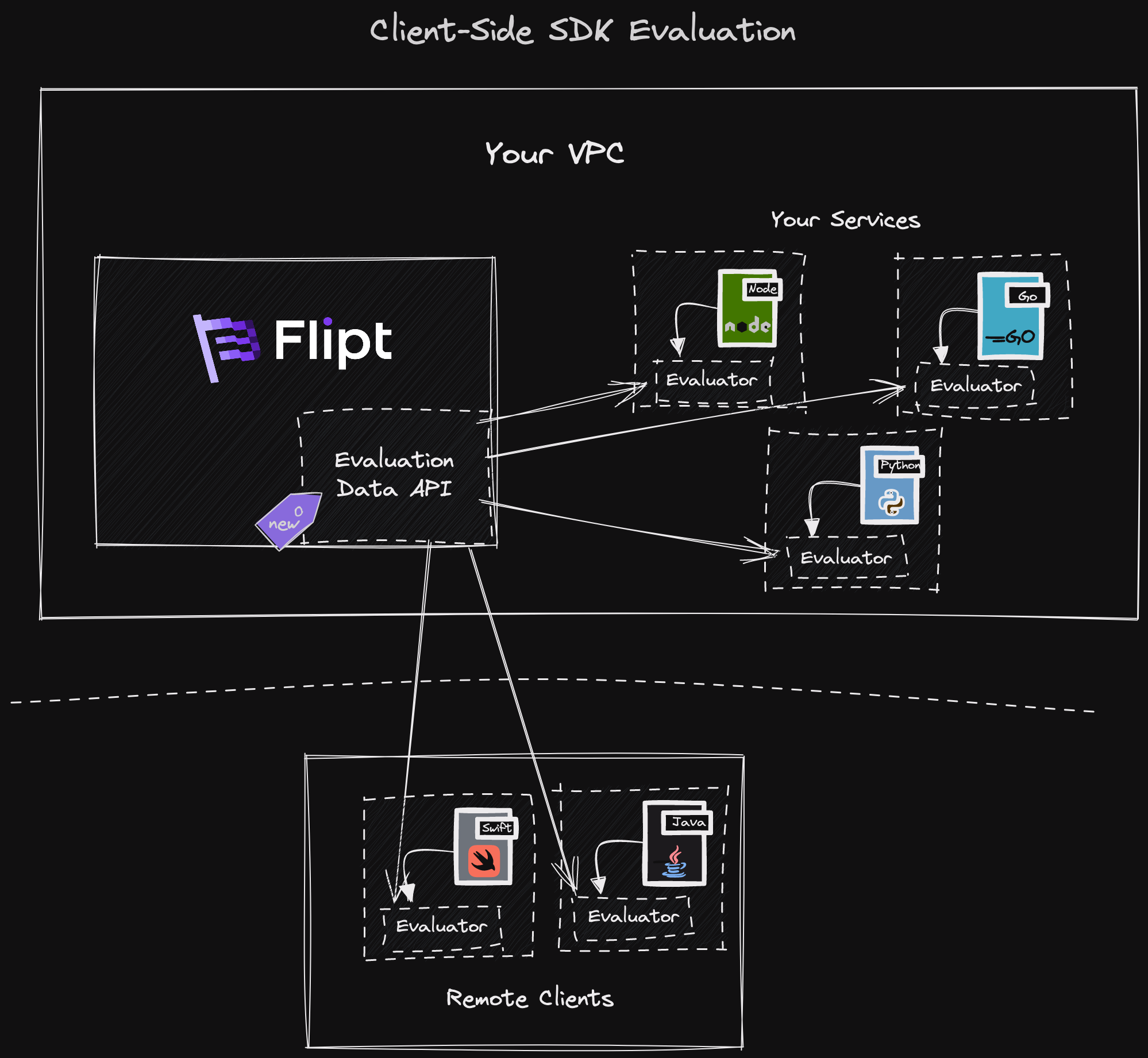
The client-side SDK engine (described below), polls this new internal API endpoint for evaluation data from a specific namespace at a configurable rate and stores this snapshot locally in memory. This approach does mean, however, that the data clients have can become out of date from the true data on the server. For example, if a flag or ruleset changes after a client has just polled, they wouldn’t receive the new updates until next time around. Allowing this polling to be configurable however, should help end-users find the best balance for their applications when it comes to when to request updated data. In the future, we will be heavily investigating supporting streaming to clients as well as caching support such as via ETAG headers to limit the amount of data transferred over the network.
Rust Core
Rust has great documentation on how to construct an FFI enabled library. Combined with this, and our excitement to get our hands dirty with Rust, we opted to write the evaluation logic in it. The transfer of the server-side evaluation logic to Rust was quite a heavy lift, but through a lot of tests, we achieved 100% parity with the server-side logic.
Engine
The Rust library has an "engine" that takes in options from a client. The options here are the upstream URL of the Flipt server from which to fetch flag state data and an update interval that tells the Rust core how often to fetch fresh data from the server. As new data is fetched, the Rust core normalizes it into data structures that make evaluations easy on the client. Also, since the data fetching happens asynchronously from client evaluations, the engine implements proper locking of shared data to be concurrency-safe.
C Interface and Dynamic Library
To allow clients to call into the Rust core, an interface needs to be established between the two languages. This is where Rust shines in allowing a library to expose C interfaces to a callee language to make use of. That interface is generated by using the cbindgen tool. The C interface uses types native to the C language which means clients would have to adapt the values they want to pass through the FFI layer using the C interface to C types. Thankfully, most languages have libraries to assist in converting their native types into C-compatible types. You can look at an example of these libraries for Python and Node to name a couple.
The C interface defines functions that the clients can depend on to be implemented by the engine. This is accomplished by compiling the Rust code down to a dynamically linked library which a host language can import and use. Without getting into too much detail, Rust supports this among other various ways of linkage, and most host languages the ability to import a dynamically linked library and use it.
FFI Snags and Considerations
When implementing an FFI Layer and languages calling into it, it's crucial to be mindful of memory management. All languages have their own way of how memory is allocated and reclaimed for use. There exists a lot of literature on this topic, but here we will briefly talk about the Rust core and what we had to do to make it work. In comparison to other popular languages, Rust’s memory management can be viewed as a somewhat complex. Rust tries to make as many compile-time guarantees as possible when it comes to variables allocated throughout the lifetime of a program as there is no garbage collector. This means that the compiler will not normally allow you to do things that would cause memory leaks or dangling pointers.
In our case, we needed to ensure that the allocated engine lives as long as the host program using the client lives. This means we have to sidestep the compile-time guarantees Rust tries to make and enter what Rust calls "unsafe" territory.
Despite the scary connotation, Rust has great support for navigating this, namely with the Box abstraction, which forces a value to live on the heap and also forces the programmer to manage its memory manually. You can see in our implementation how we used Box and passed back a void pointer back through the FFI layer to the client. This pointer is then deallocated when the host program calls this function.
Host Languages
For our initial launch, we are supporting four languages: Node, Python, Ruby, and Go, but we will soon be adding support for additional languages.
Most of these initial languages have native libraries to convert types into C types, which made the client implementations very thin. For example, you can see the Go implementation only spans two files (excluding tests) and less than 200 lines of code!
Each of these clients exposes an API that should be a bit familiar if you have used our other server-side clients.
EvaluateVariant: takes in a flag key, entity ID, and context and returns a variant evaluationEvaluateBoolean: takes in a flag key, entity ID, and context and returns a boolean evaluation
It depends on the language of how the values are passed, however it should not differ too much from one to the next. There are also other instructions and considerations on the README for each client on how to manage the allocated memory of the engine throughout the lifetime of the program. It all boils down to calling the destroy_engine method on the C API which is called behind a native language class method.
Packaging and Distribution
Packaging of these clients is an area in which we are actively exploring. The nature of these libraries being dynamically linked and hard to embed makes packaging challenging. Currently, there is no published client for any of the languages, but there are instructions on each language README on how to build the client and use it within your application.
Since the dynamic library (engine) is platform-dependent, we need to build it for each platform (ex: x86, ARM, Windows) and include it in each 'native' language library in order to then package and publish consumable SDKs to the various registries. We would love any feedback or thoughts on how to best package the SDKs and shared libraries for each language/platform. If you have any ideas, please do not hesitate to reach out to us on Github or Discord.
Performance Comparison
The big win for evaluations moving to the client side is the performance gain that comes with it. Wherever the evaluations are happening, server or client-side, each come with different overheads and trade-offs in regards to performance and memory. For client-side evaluation, you are making the sacrifice for better evaluation speed by incurring more memory build-up wherever the client is located. This can be an acceptable trade-off in many use cases.
The graph below shows the millisecond duration of evaluations between our server-side SDK vs. the new client-side solution out of 1000 evaluations. Keep in mind that the y-axis here is of logarithmic scale (base 10).
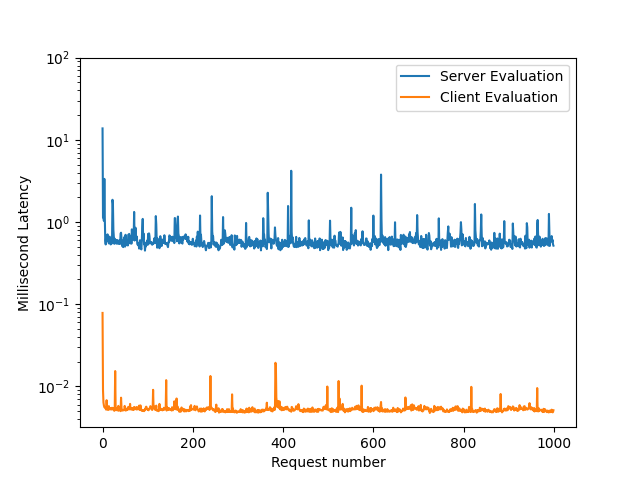
The variance between the two lines is significant, which is why we needed the logarithmic scale on the y-axis. Evaluation latency with the server-side SDK against the server ranged from 0-14 milliseconds, while the client-side evaluation latency ranged from 0-0.1 milliseconds. That's a 1000x improvement in evaluation latency!
Conclusion
Today, you can check out our newly open-sourced repository flipt-client-sdks and start building and integrating these clients into your applications to try client-side evaluation with Flipt!
As mentioned above, if any of this excites you, especially the packaging part please do not hesitate to reach out to us on Github, Discord, or X, we would love to hear your feedback and opinions!
Related Posts

February 16, 2024
Elevating Feature Flag Analytics in Flipt
A deep dive into the latest release of Flipt, featuring first-class analytics for feature flag evaluations.

May 3, 2023
Audit Events for Flipt
How we leveraged OpenTelemetry for generating audit events

October 25, 2023
Experimenting on the Edge
Exploring libSQL, sqld, and Turso to run feature flags on the edge